Deep learning is a field of AI and machine learning that tackles image classification, computer vision, NLP, and other complex tasks with uncategorized data.
A deep neural network is a neural network with at least three layers in total (one hidden layer). The network performs the task of deep learning on multiple hidden computation layers.
Regardless of whether the network implements supervised, semi-supervised, or unsupervised learning, programming a deep learning network from scratch is tiresome and involves a lot of high-level math and computation.
Thankfully, there are many frameworks available today that aid in creating a neural network. The frameworks provide specific pre-programmed workflows, allowing you to develop and train a deep learning network in no time.

What Are the Most Popular Deep Learning Frameworks?
The most popular deep learning frameworks today are:
- TensorFlow (TF)
- PyTorch
- Keras
- SciKit-Learn (SKLearn)
- Apache MXNet
- Eclipse Deeplearning4j (DL4J)
- MATLAB
- Sonnet
- Chainer
- Flux
Each framework comes with a unique set of features and applications. Below is a brief overview of each framework’s characteristics and advantages.
1. TensorFlow
TensorFlow is an open-source machine learning and AI framework. The framework focuses on creating deep neural networks, although many additional machine learning tasks are possible.
Developed by the Google Brain team for internal research and production, the initial release was in 2015. The newer and updated version (TensorFlow 2.0) was released in 2019.
TensorFlow Features
- Programming language variety. Developers most often use TensorFlow in Python to ensure stability. Support for other languages is available, too, such as JavaScipt, C++, and Java. Versatility in programming languages allows a broader range of industry applications.
- Eager Execution. The eager execution environment provides immediate results, allowing insight into a neural network operation as it happens.
- Built-in primitive neural network executions. TensorFlow features many built-in functions used in programming a neural network. One such feature is the tf.nn module for various neural network operations.
TensorFlow Advantages
- Open source. TensorFlow is an open-source system available for everyone at no cost. Whether you are test driving TensorFlow, using it for educational purposes, or applying neural networks at an industry level, the technology is ready for development.
- A plethora of learning materials. Since TensorFlow is one of the most popular deep learning frameworks, there is a lot of free learning material available online. Google even provides CoLab, an in-browser notebook environment preinstalled with TensorFlow and readily available GPUs.
- Parallelism. TensorFlow distributes training across multiple resources, such as GPUs and CPUs, or TPUs (Tensor Processing Units). The feature is handy for deep learning networks with many layers and parameters.
- Scalability. Transitioning from shared memory to distributed memory is seamless with TensorFlow. Deep learning workloads snowball, and the distributed solutions in TensorFlow 2.0 provide infinite scalability.
Not sure where GPUs fit into the picture? Learn why GPUs and deep learning go together and how GPU powers the future of machine learning.
2. PyTorch
PyTorch is an open-source machine learning and neural network framework based on Torch. The primary focus of PyTorch is on computer vision and NLP (natural language processing) tasks, with various scientific computing features.
Developed by Facebook’s AI Research Lab (FAIR), PyTorch’s initial release was in 2016. The library is available with Python and C++, although the Python library provides stability.
PyTorch Features
- GPU accelerated computations. PyTorch has similar computation features to the NumPy. Instead of arrays, PyTorch uses tensors as n-dimensional arrays. The critical difference is GPU-powered computation, where PyTorch provides a massive computation speed acceleration required for deep learning.
- Automatic differentiation. Implementing forward and backward passes through a deep learning network is cumbersome, and PyTorch offers the autograd package for easy gradient computation.
- Built-in neural network executions. Like TensorFlow, PyTorch offers the torch.nn package that has a set of modules with standard neural network functionalities.
PyTorch Advantages
- Easy to learn. The framework is open source and well documented, with plenty of example tutorials and codes. The library has a Python feel to it.
- Simple debugging. Debugging integration with tools such as pdb, ipdb, and Python IDEs such as PyCharm eases the computational graph debugging process.
- Parallelism. Parallel training on multiple resources through the torch.nn.parallel wrapper allows custom computational task distribution.
- Library extensions. PyTorch has a rich community presence among both developers and researchers, making it easy to extend the framework with various APIs and enhance PyTorch deep learning networks.
See how the two most popular machine learning libraries compare: PyTorch vs. TensorFlow.
3. Keras
Keras is an artificial neural network library and the high-level front-end for TensorFlow. Up until recently, Keras supported various back-ends, while the newest version (2.4) supports only TensorFlow.
The Keras library focuses explicitly on creating neural network building blocks. The library aims to simplify neural network creation and facilitates deep learning on mobile devices, webpages, and JVMs.
Keras Features
- Beginner friendly. Keras is very user-friendly for developers new to deep learning. The robust framework is simple but not unsophisticated. Advanced users benefit from the front-end framework to simplify TensorFlow computation processes.
- Pre-labeled datasets. Commonly used demonstration and learning datasets are available in the Keras library. The data is clean, labeled, and ready for experimenting with. Examples include handwritten digits, IMDB reviews, Boston housing prices, etc.
- Predefined layers, parameters, and preprocessing functions. Keras features readily available neural network layers and various loss and optimization functions. Additionally, the framework has different preprocessing functions for data preparation.
Keras Advantages
- Easy to write and deploy. The code is simple and easily deployed. The documentation is comprehensive and clearly laid out. Keras allows building a neural network with just a few lines of code.
- Built-in data parallelism. The framework has built-in support for multiple GPUs to distribute the neural network training.
- Pretrained models. Learning and implementing everything from scratch takes time. Take advantage of the pre-trained Keras models and work from a readily available setup.
- Large community support. The Keras framework often appears in coding challenges and various data science and machine learning communities.
Follow our guide to install Keras with TensorFlow back-end on Linux.
4. SciKit-Learn (SKLearn)
SciKit-Learn (also known as SKLearn) is an open-source machine learning library built on NumPy, SciPy, and matplotlib. Although the framework is a general-purpose machine learning library, some deep learning functionalities exist.
SciKit-Learn is not typically used for large-scale applications due to the lack of GPU support.
SciKit-Learn Features
- Built-in datasets. SciKit-Learn comes with datasets prepared for machine learning algorithms. Some initial datasets include the Iris dataset, diabetes dataset, housing prices, etc.
- Data splitting. When working with datasets for any algorithm, a common task is to split the dataset into a train and test group (typically 70-30 or 80-20). SKLearn’s train_test_split function helps with this task.
- Multi-Layer Perceptron algorithm (MLP). SciKit-Learn features the multi-layer perceptron algorithm as a function. The MLP algorithm is a subset of deep neural networks with only feed-forward propagation and usually fewer hidden layers than a deep learning network. MLPs are an essential building element for deep learning.
SciKit-Learn Advantages
- User friendly. The framework often appears in academic and learning environments due to the straightforward nature of the code.
- Useful toolkit. SciKit-Learn offers a noteworthy data preprocessing and feature engineering toolkit. Even when not used as a stand-alone framework, the tools come in handy when combined with other powerful deep learning frameworks.
5. Apache MXNet
Apache MXNet is a software-based open-source deep learning framework. The Apache Software Foundation's framework supports many deep learning models.
Various research institutions and cloud providers support MXNet, and it is the chosen deep learning framework for AWS.
MXNet Features
- Scalability. MXNet supports distribution on dynamic cloud infrastructure with multiple CPUs and GPUs.
- Portability. The framework supports the deployment of pre-trained networks on low-end machines and devices. For example, a deep learning network trained on a high-level machine can easily be transported to IoT, mobile, edge, or serverless devices.
- Flexible programming. Both imperative and symbolic programming is available. During development, bug tracking, checkpoints, hyperparameter modification, and early stopping are all possible.
MXNet Advantages
- Multiple language support. For front-end development, MXNet supports eight programming languages (Python, R, Scala, Clojure, Julia, Perl, MATLAB, and JavaScript). The supported language for back-end optimization is C++. This language versatility provides broad development applications.
- Suitable for both business and academia. The software is computationally efficient for both industry and research applications.
- High-performance API. The framework handles near-linear scalability for managing large projects in less time.
Missing data is a frequent problem in data science and machine learning. Read up on how to handle missing data in Python.
6. Eclipse Deeplearning4j (DL4J)
Deeplearning4j is a suite of deep learning tools that run on JVM (Java Virtual Machine). The framework relies on Java, with additional support and APIs for other languages.
Deeplearning4j supports a wide variety of deep learning algorithms, including a distributed parallel version for each algorithm.
Deeplearning4j Features
- Keras support. This deep learning framework works with TensorFlow and can import models from other Python frameworks through Keras.
- Hadoop and Spark integration. Apache Spark integration enables deep learning pipelines directly on Spark clusters and applies deep learning to big data.
- CUDA integration. GPU optimization through CUDA is available and distributed through Hadoop or OpenMP.
Deeplearning4j Advantages
- JVM compatibility. JVM compatibility supports any JVM-based language, such as Clojure or Scala.
- Keras support. DL4J supports the Python API through the Keras framework.
- Distributed mindset. Natural integration with Spark clusters and the Hadoop ecosystem provides a wide range of distributed programming functionalities.
7. MATLAB
MATLAB is proprietary software with support for deep learning. The software caters to engineers, mathematicians, scientists, and other professionals without experience in the deep learning field.
The framework aims to create a deep learning network with minimal coding through various tools and extensions.
MATLAB Features
- Non-programmer friendly. MATLAB requires minimal coding to create, visualize, and use deep learning models. Importing pre-trained models is supported and easy to configure.
- Automated deployment. MATLAB integrates with all kinds of environments and automates deployment on enterprise systems, embedded devices, clusters, or in-cloud.
- Interactive labeling. The framework allows interactive object labeling, bringing better results quickly.
MATLAB Advantages
- Good for learning. MATLAB makes deep learning practical and accessible. Users with less coding experience can apply deep learning techniques in their domain.
- Interactive. Various apps for data preprocessing help automate the data labeling processes. This allows the direct application of signal processing on raw IoT and edge device data.
- Collaborative. MATLAB integrates TensorFlow and allows pre-trained models to be used directly within the environment. Although the software is not open source, there is plenty of collaboration with open-source software.
8. Sonnet
Sonnet is a deep learning framework built on top of TensorFlow 2. The module-based framework aims to create simple actions and constructs for machine learning processes.
Developed by DeepMind researchers, Sonnet serves many different neural network construction purposes.
Sonnet Features
- Predefined modules. Sonnet features commonly used deep learning modules, such as 2D convolution, batch normalization, etc. If anything is missing, creating a custom module is simple.
- Predefined network modules. Besides layer modules and constructs, Sonnet also has predefined network modules, such as MLP (Multi-Layer Perceptron).
- Simplicity. The framework does everything through a single concept: snt.module. This simple yet powerful tool ensures every model is independent and self-contained.
Sonnet Advantages
- Distributed training freedom. The Sonnet module does not apply additional operations to data when shifting to distributed strategies, therefore providing complete control over the distributed training process.
- Modular. Defining custom modules and declaring submodules internally during the construction process provides many customization options during development.
- TensorFlow focused. Sonnet works with TensorFlow and integrates seamlessly with raw code and other high-level libraries. TensorFlow details are accessible through the Sonnet framework directly.
9. Caffe
Caffe is an open-source deep learning framework written in C++ with a Python front-end. Developed at UC Berkley, the framework was started as a project by PhD student Yangqing Jia.
The framework specializes in image classification and segmentation, although other deep learning architectures are also possible.
Caffe Features
- Expressive architecture. Configuration and models are not hard-coded. Switching between GPU and CPU settings happens through flag switching.
- Speed. Caffe processes over 60M images a day on a single GPU. As one of the fastest convolutional network frameworks, it is excellent for research and industry applications.
- Actively developed. The framework has a highly active community. Custom distributions with optimizations for specific processors exist.
Caffe Advantages
- Various interface support. Caffe supports interfaces such as C, C++, Python, and MATLAB. Additionally, the framework works directly from the command line.
- Pre-trained networks through Caffe Model Zoo. The C++ library Caffe Model Zoo contains pre-trained networks ready for use immediately.
- OpenMP support. Caffe features support for the OpenMP API, enabling multithreading and parallelism.
10. Flux
Flux is a Julia machine learning framework focusing on high-performance production pipelines. The framework features a layer-stacking-based interface to simplify models.
The framework supports operations with other Julia packages and helps reinforce the security of machine learning models.
Flux Features
- Differentiable programming. Flux features automatic differentiation, and gradient computation is an effortless task in this framework.
- TPU support. Flux deep learning models compile to TPUs for cloud computing. The code also runs directly from Google Colab notebooks.
- Advanced GPU support. The GPU kernels can be customized directly in Julia through the CUDA.jl package. Tweaking the code allows customization of GPU code, gradients, and layers.
Flux Advantages
- Pretrained models through Model Zoo. Like Caffe, Flux also provides pre-trained models for computer vision, text-based models, and gaming through the Model Zoo. The models enable the broad application of Flux.
- Custom abstraction levels. Whether you prefer to build a model from scratch or use ready-made models, Flux leaves the choice to the developer.
- Extensibility. Flux provides diverse extensibility through various packages that enhance the deep learning workflow in multiple situations.
Which Deep Learning Framework is the Most Popular?
Currently, the top four most popular frameworks are:
- PyTorch
- TensorFlow
- Scikit-Learn
- Keras
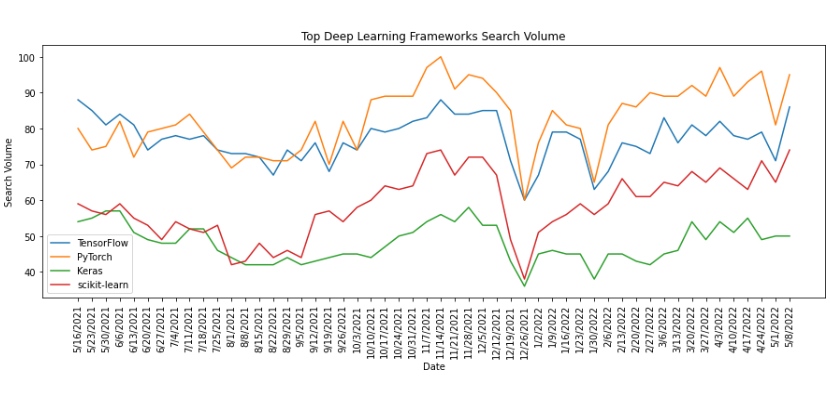
Analyzing the Google search volume for each framework shows that as of May 2022, the most searched deep learning network worldwide is PyTorch. The framework is popular in the ML community for the Pythonic and more straightforward approach to deep learning when compared to other frameworks (especially TensorFlow).
Each framework has a task where it shines, and some frameworks even work happily together instead of competing for the top position. A standard method is to use TensorFlow with Keras as the front-end and scikit-learn for data preprocessing.
Which Deep Learning Framework is Easiest to Learn?
Deep learning is a challenging subject to master, and the sheer amount of information is overwhelming when starting on the deep learning path.
The two commonly used frameworks for education purposes are:
- Keras
- Scikit-Learn
These two frameworks dominate the educational field because they make picking up basic deep learning principles and terminology easy. The knowledge gained through them applies to any deep learning framework.
Once you master the skills from these two frameworks, moving to a more mature environment such as TensorFlow or PyTorch is best because of to the vast amount of documentation, information, and available examples.
Conclusion
Businesses leverage the power of data through various deep learning frameworks, and each framework provides a unique feature in the deep learning world.
Most of the frameworks are open source and free to try out. There are also many courses and information available online as a result of the growing popularity of AI and machine learning. Mastering deep learning is now easier than ever.




