Introduction
Elastic Stack, formerly known as the ELK stack, is a popular suite of tools for ingesting, viewing, and managing log files. As open-source software, you can download and use it for free (though fee-based and cloud-hosted versions are also available).
This tutorial introduces basic ELK Stack usage and functionality.

Prerequisites
- A system with Elasticsearch installed
What is ELK Stack?
ELK stands for Elasticsearch, Logstash, and Kibana. In previous versions, the core components of the ELK Stack were:
- Elasticsearch – The core component of ELK. It works as a searchable database for log files.
- Logstash – A pipeline to retrieve data. It can be configured to retrieve data from many different sources and then to send to Elasticsearch.
- Kibana – A visualization tool. It uses a web browser interface to organize and display data.
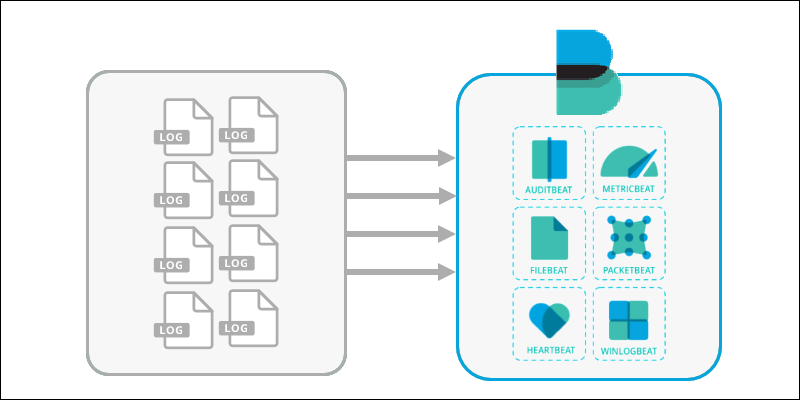
Additional software packages called Beats are a newer addition. These are smaller data collection applications, specialized for individual tasks. There are many different Beats applications for different purposes. For example, Filebeat is used to collect log files, while Packetbeat is used to analyze network traffic.
Due to the ELK acronym quickly growing, the Elastic Stack became the more satisfactory and scalable option for the name. However, ELK and Elastic Stack are used interchangeably.
Note: Need to install the ELK stack to manage server log files Follow this step-by-step guide and set up each layer of the stack – Elasticsearch, Logstash, and Kibana for Centos 8 or Ubuntu 18.04 / 20.04.
Why Use ELK Stack?
The ELK stack creates a flexible and reliable data parsing environment. Organizations, especially ones with cloud-based infrastructures, benefit from implementing the Elastic stack to address the following issues:
- Working on various servers and applications creates large amounts of log data, which is not human readable. The ELK stack serves as a powerful centralized platform for collecting and managing unstructured information, turning it into useful assets in the decision-making process.
- The ELK stack with basic features is open source, which makes it a cost-efficient solution for startups and established businesses alike.
- The Elastic stack provides a robust platform for performance and security monitoring, ensuring maximal uptime and regulation compliance.
The Elastic stack addresses the industry gap with log data. The software can reliably parse data from multiple sources into a scalable centralized database, allowing both historic and real-time analysis.
How Does Elastic Stack Work?
The Elastic stack follows certain logical steps, all of which are configurable.
1. A computer or server creates log files. All computers have log files that document events on the system in a hard-to-read format. Some systems, such as server clusters, generate massive amounts of log files.
However, Elastic Stack is designed to help manage scalable amounts of data.
2. The various available information files are collected by a Beats application. Different Beats reach out to different parts of the server, read the files, and ship them out.
Some users may skip Beats altogether and use Logstash directly. Others may connect Beats directly to Elasticsearch.
3. Logstash is configured to reach out and collect data from the different Beats applications (or directly from various sources).
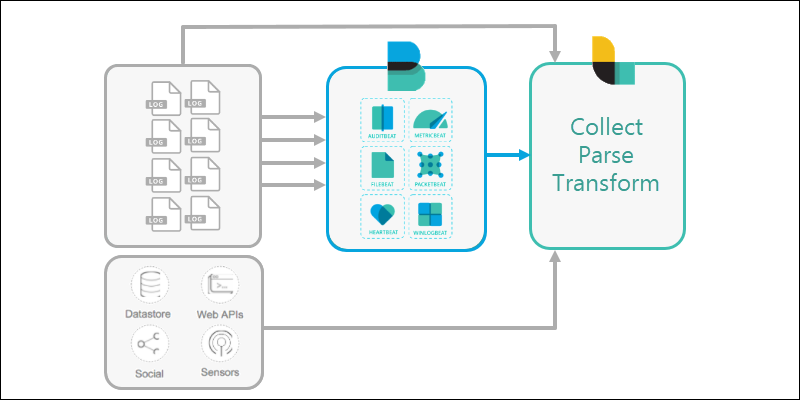
In larger configurations, Logstash can filter data from multiple systems, and collect the information into one location.
4. Elasticsearch is used as a scalable, searchable database to store data. Elasticsearch is the warehouse where Logstash or Beats pipe all the data.
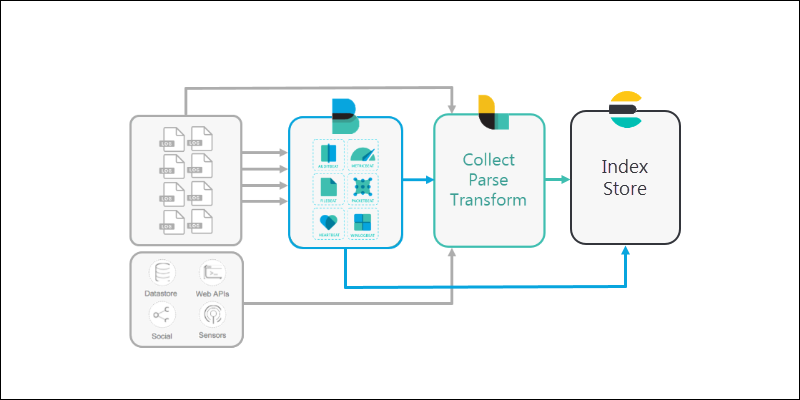
5. Finally, Kibana provides a user-friendly interface for you to review the data that’s been collected.
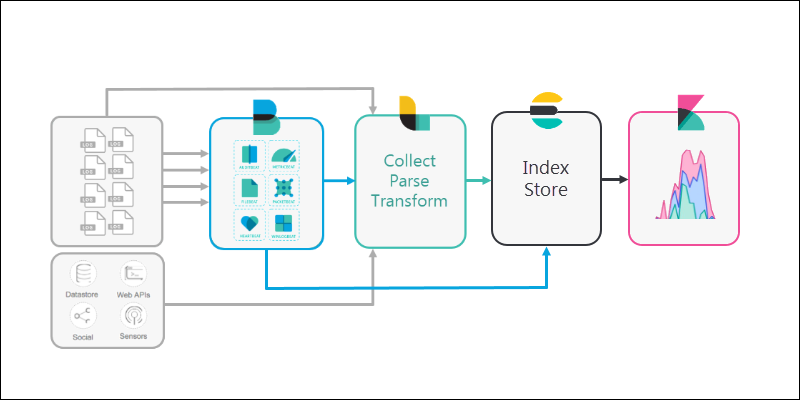
It is highly configurable, so you can adjust the metrics to fit your needs. Kibana also provides graphs and other tools to visualize and interpret patterns in the data.
ELK Stack Supporting Applications
Additional third-party applications enhance the Elastic Stack, providing wider use-case possibilities. Some external applications supported by the ELK stack are:
- Apache Kafka
Kafka is a real-time streaming distribution platform. That means that it can read multiple data sources at once. Kafka acts as a data buffer and helps prevent data loss or interruption while streaming files quickly.
Note: Working with a Kubernetes cluster? Learn how to set up Apache Kafka on Kubernetes.
- Redis
Redis is a NoSQL key-value database with incredible read/write speeds and various data types. When added to the Elastic stack, Redis often serves as a buffer for data stream spikes, ensuring no data is lost.
- Hadoop
Hadoop is a massive batch processing data storage system. Indexing data from Hadoop into the real-time Elasticsearch engine creates an interactive bi-directional data discovery and visualization platform.
The Hadoop support comes through the Elasticsearch-Hadoop Connector, offering full support for Spark, Streaming, Hive, Storm, MapReduce, and other tools.
- RabbitMQ
RabbitMQ is a messaging platform. Elastic Stack users use this software to build a stable, buffered queue of log files.
- Nginx
Nginx is best known as a web server that can also be set up as a reverse-proxy. It can be used to manage network traffic or to create a security buffer between your server and the internet.
ELK Stack Advantages and Disadvantages
The Elastic stack comes with certain benefits and drawbacks.
Advantages
- The Elastic stack and the components are free to try out and use.
- ELK offers numerous hosting options, whether on-premises or deployed as a managed service.
- The capability to centralize logging from complex cloud environments allows advanced searches and creating correlation from multiple sources on a single platform.
- Real-time analysis and visualization decrease the time taken to discover insights, enabling continual monitoring.
- Client support for multiple programming languages, including JavaScript, Python, Perl, Go, etc.
Disadvantages
- Deploying the stack is a complex process and depends on the requirements. Check out our tutorial for deploying the Elastic stack on Kubernetes.
- Growing and maintaining the ELK stack is costly and requires computing and data storage based on the data volume and storage time.
Note: Deploy Bare Metal Cloud server instances based on your specific needs as you need them. Choose from one of our pre-configured computing, storage or memory instances and pick a billing model that best fits your budget.
- Stability and uptime become problematic as the data volumes grow due to non-existent indexing limits.
- Data retention and archiving requires multiple nodes, computing power, and resources in general.
Elasticsearch Overview
Elasticsearch is the core of the Elastic Stack. It has two main jobs:
- Storage and indexing of data.
- Search engine to retrieve data.
Technical Elasticsearch details include:
- Robust programming language support for clients (Java, PHP, Ruby, C#, Python).
- Uses a REST API – Applications written for Elasticsearch have excellent compatibility with Web applications.
- Responsive results – Users see data almost in real-time.
- Distributed architecture – Elasticsearch can run and connect between many different servers. The Elastic Stack can scale easily as infrastructure grows.
- Inverted indexing – Elasticsearch indexes by keywords, much like the index in a book. This helps speed up queries to large data sets.
- Shards – If your data is too large for your server, Elasticsearch can break it up into subsets called Shards.
- Non-relational (NoSQL) – Elasticsearch uses a non-relational database to break free from the constraints of structured/tabular data storage.
- Apache Lucene – This is the base search engine that Elasticsearch is based on.
Note: If you are working on an Ubuntu system, take a look at How to Install Elasticsearch on Ubuntu 18.04.
Logstash Overview
Logstash is a tool for gathering and sorting data from different sources. Logstash can reach out to a remote server, collect a specific set of logs, and import them into Elasticsearch.
It can sort, filter, and organize data. Additionally, it includes several default configurations, or you can create your own. This is especially helpful for structuring data in a way that’s uniform (or readable).
Logstash technical features:
- Accepts a wide range of data formats and sources – This helps consolidate different data sets into one central location.
- Manipulates data in real-time – As data is read from sources, Logstash analyzes it and restructures it immediately.
- Flexible output – Logstash is built for Elasticsearch, but like many open-source projects, it can be reconfigured to export to other utilities.
- Plugin support – A wide range of add-ons can be added to enhance Logstash’s features.
Kibana Overview
You can use Elasticsearch from a command line just by having it installed. But Kibana gives you a graphical interface to generate and display data more intuitively.
Here are some of the technical details:
- Dashboard interface – Configure graphs, data sources, and at-a-glance metrics.
- Configurable menus – Build data visualizations and menus to quickly navigate or explore data sets.
- Plug-ins – Adding plug-ins like Canvas allow you to add structured views and real-time monitoring to your graphical interface.
Learn how to use Kibana in our guide Complete Kibana Tutorial to Visualize and Query Data.
Beats Overview
Beats runs on the system it monitors. It collects and ships data to a destination, like Logstash or Elasticsearch.
You can use Beats to import data directly into Elasticsearch if you’re running a smaller data set.

Alternatively, Beats can be used to break data up into manageable streams, then parsed into Logstash, to be read by Elasticsearch.

For a single server, you can install Elasticsearch, Kibana, and a few Beats. Each Beats collects data and sends it to Elasticsearch. You then view the results in Kibana.
Alternatively, you can install Beats on several remote servers, then configure Logstash to collect and parse the data from the servers. That data is sent to Elasticsearch and then becomes visible in Kibana.
| Beat | Data Capture | Description |
|---|---|---|
| Auditbeat | Audit data | A supercharged version of Linux auditd. It can interact directly with your Linux system in place of the auditd process. If you already have auditd rules in place, Auditbeat will read from your existing configuration. |
| Filebeat | Log files | Reads and ships system logfiles. It is useful for server logs, such as hardware events or application logs. |
| Functionbeat | Cloud data | Ships data from serverless or cloud infrastructure. If you’re running a cloud-hosted service, use it to collate data from the cloud and export it to Elasticsearch. |
| Heartbeat | Availability | Displays uptime and response time. Use this to keep an eye on critical servers or other systems, to make sure they’re running and available. |
| Journalbeat | Systemd journals | Forwards, centralizes and ships systemd journal logs. |
| Metricbeat | Metrics | Reads metric data - CPU usage, memory, disk usage, network bandwidth. Use this as a supercharged system resource monitor. |
| Packetbeat | Network traffic | Analyzes network traffic. Use it to monitor latency and responsiveness, or usage and traffic patterns. |
| Winlogbeat | Windows event logs | Ships data from the Windows Event Log. Track logon events, installation events, even hardware or application errors. |
ELK Stack Use Cases
Real-time log monitoring from various resources provides the Elastic stack with many creative use cases.
- Security monitoring and alerting. A server monitoring and alerting system is an important security application for the ELK stack. Checking for unusual request or detecting server attacks with a real-time alert system can help mitigate damages as soon as they appear.
- E-commerce solutions. Full-text searches, indexing, aggregations and fast responses creates a better user experience. Visually monitoring search trends and behaviors helps enhance trend analysis.
- Web scraping. The ability to collect, index and search through unstructured data from varying sources makes it simple to gather and visualize web scraped information.
- Traffic monitoring. Monitoring website traffic data helps indicate that one server is overloaded. Implement a load-balancing application (like Nginx) to shift traffic to other servers.
- Error detection. If you’re deploying a new application, you can monitor errors for that application. These can help quickly identify areas to fix bugs or improve application design.
Elastic Stack generates data that you can use to solve problems and make sound business decisions.
Conclusion
In this Elk Stack Tutorial, you learned the basics of the Elastic Stack, how it is used, what it is used for, and its components.
Review the use cases, and consider trying out the ELK stack or learn about Splunk, an alternative to ELK stack, in our ELK Stack vs Splunk article.
