Introduction
MySQL is a database application that stores data in rows and columns of different tables to avoid duplication. Duplicate values can occur, which can impact MySQL performance.
This guide will show you how to find duplicate values in a MySQL database.

Prerequisites
- An existing installation of MySQL
- Root user account credentials for MySQL
- A command line / terminal window
Setting up a Sample Table (Optional)
This step will help you create a sample table to work with. If you already have a database to work on, skip to the next section.
Open a terminal window, and switch to the MySQL shell:
mysql –u root –pNote: If you get ‘ERROR 1698’, try opening MySQL using sudo mysql instead. This error occurs on some Ubuntu installations and is caused by authentication settings.
List existing databases:
SHOW databases;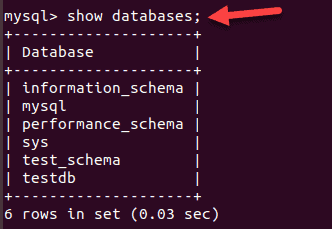
Create a new database that doesn’t already exist:
CREATE database sampledb;Select the table you just created:
USE sampledb;Create a new table with the following fields:
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);Insert rows into the table:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');Run the following SQL query:
SELECT * FROM dbtable
ORDER BY date_x;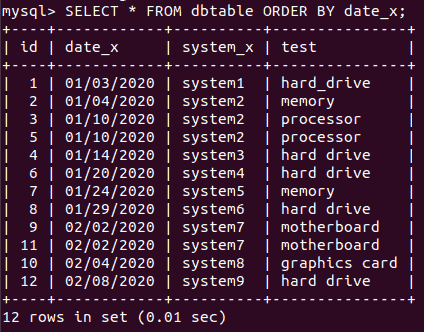
Finding Duplicates in MySQL
Find Duplicate Values in a Single Column
Use the GROUP BY function to identify all identical entries in one column. Follow up with a COUNT() HAVING function to list all groups with more than one entry.
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
Find Duplicate Values in Multiple Columns
You may want to list exact duplicates, with the same information in all three columns.
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

This query works by selecting and testing for the >1 condition on all three columns. The result is that only rows with duplicate values are returned in the output.
Check for Duplicates in Multiple Tables With INNER JOIN
Use the INNER JOIN function to find duplicates that exist in multiple tables.
Sample syntax for an INNER JOIN function looks like this:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
To test this example, you need a second table that contains some information duplicated from the sampledb table we created above.
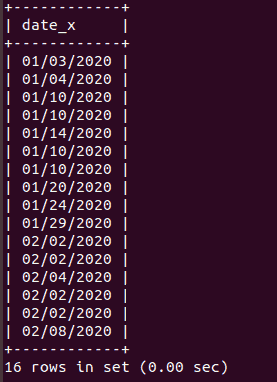
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
This will display any duplicate dates that exist between the existing data and the new_table.
Note: The DISTINCT command can be used to return results while ignoring duplicates. Also, newer versions of MySQL use a strict mode, which can affect operations that attempt to select all columns. If you get an error, make sure that you’re selecting specific individual columns.
Conclusion
Now you can check for duplicates in MySQL data in one or multiple tables and understand the INNER JOIN function. Make sure you created the tables correctly and that you select the right columns.
Now that you have found duplicate values, learn how to remove MySQL duplicate rows.
